2025年还能开无人自助棋牌室吗
前言: 吴思先生在《潜规则》(中国历史中的真实游戏)一书中讲述了很多生动、有趣的官场故事,透过历史表象,揭示出隐藏在正式规则之下、实际上支配着社会运行的不成文的规矩, 非常值得阅读。
这篇文章准确来讲并不是计算机/软件开发的潜规则, 实际上是那些你可能在使用,却没有注意到的一些原理和规律,这些东西很重要,掌握了能够指导你以后的开发和设计。
和码农翻身公众号之前的文章不同, 这是一篇没有故事,读起来不那么好玩的超级干货, 我建议你静下心来,阅读一遍, 仔细的思考一下, 绝对物超所值。
1. 上帝的规矩:局部性原理
这个原理讲的是在一段时间里, 整个程序的执行仅限于程序的某一个部分, 相应的, 程序访问的存储空间也局限于某一个内存区域, 具体分为:
(1) 时间局部性:是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行; 如果某数据被访问,则不久之后该数据可能再次被访问。
(2) 空间局部性: 是指一旦程序访问了某个存储单元,则不久之后。其附近的存储单元也将被访问。
为什么是这样? 我也不知道, 可能是计算机界的上帝定下的规矩。
但是这个原理的用处可就大了, 例如Java 虚拟机, 本来是解释执行.class 文件,性能不怎么样, 但是利用局部性原理, 就可以找到那些常用的, 所谓的热点(Hotspot)代码, 然后把他们编译成本地原生代码(native code), 这样执行效率就和C/C++差不多了。
当然这个原理更大的用处就是下面要提到的缓存。
2. 坐飞机的怎么和坐驴车的打交道: 缓存
为什么需要缓存(Cache)?
本质的原因是速度的不匹配。
CPU比内存快100多倍, 比硬盘快1000多万倍。
如果CPU每次做事的时候, 都等着内存和硬盘, 那整个计算机的速度估计要慢的要死了。
所以根据局部性原理, 操作系统会把经常需要用的数据从硬盘取到内存, CPU 会把经常用的数据从内存取到自己的缓存中。
(参见文章《CPU阿甘》)
通过这种办法等待的问题能带到极大的缓解。
在Web 开发中,缓存更是非常常见的, 由于数据库(硬盘)太慢, 大部分Web系统都会把最常用的业务数据放到内存中缓存起来。
3. 抛弃细节: 抽象
抽象是计算机科学中最为重要的概念之一。
当我们遇到复杂问题的时候, 抽象是非常重要的武器。
《深入理解计算机系统》一书中提到:
“指令集是对CPU的抽象, 文件是对输入/输出设备的抽象, 虚拟存储器是对程序存储的抽象, 进程是对一个正在运行的程序的抽象, 而虚拟机是对整个计算机(包括操作系统、处理器和程序)的抽象。”— 总结的非常精辟
CPU集成电路硬件无比复杂, 但是我们写程序肯定不用接触这些硬件细节, 那样就累死了, 我们只要遵循CPU的指令集, 程序就可以正确的运行, 而不用关心指令在硬件层次到底是怎么运行的。
硬盘也是这样, 有磁道,柱面,扇区, 我们写应用层程序也不用和这些烦人的细节打交道, 在操作系统和设备驱动的配合下, 我们只需要面对一个个“文件”,打开,读取,关闭就行了。 操作系统会把逻辑的文件翻译成物理磁盘上的字节。
再比如为了实现数据的共享,数据的一致性和安全性,需要大量的,复杂的程序代码来实现, 每个应用程序都实现一份肯定不是现实的。 所以计算机科学抽象出了一个叫数据库的东西, 你只需要安装数据库软件, 使用SQL和事务就能实现多用户对数据的安全访问了。
参见文章《抽象, 程序员必备的能力》
4. 我只想和邻居打交道: 分层
分层其实也是抽象的一种,它通过层次把复杂的,可能变化的东西隔离开来, 某一层只能访问它的直接上层和下层, 不能跨层访问。
例如网络协议分层:
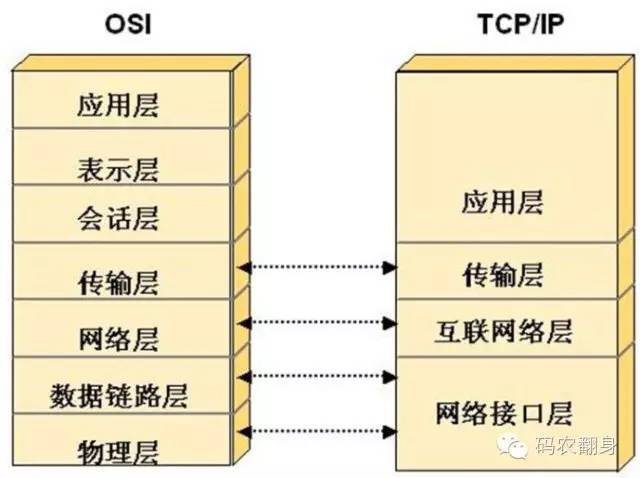
再比如Web开发的分层:

分层的好处就是隔离变化, 在接口不变的情况下, 某一层的变化只会局限于本层次内。
即使是接口变化, 也仅仅会影响调用方。
5. 我怕等不及: 异步调用
当你的程序需要等待一个长时间的操作而被阻塞住时而无所事事的时候, 异步调用就派上用场了。
异步调用简单就是说: 我等不及你了, 先去做别的事情, 你做完了告诉我一声。
回到最早的那个CPU的例子, CPU速度太快, 当它想读取硬盘文件的时候,是不会等待慢1000多万倍的硬盘的, 它会启动一个DMA , 不用通过CPU, 直接把数据从硬盘读到内存, 读完以后通过中断的方式来通知CPU。
Node.js 和 Web服务器Nginx 也是这样, 一个线程或若干个线程处理所有的请求, 遇到耗时的操作, 绝不等待, 马上去干别的事情,等到耗时操作完成后,再来通知这些干活的线程。
还有著名的AJAX , 当浏览器中的javascript发出一个Http 请求的时候, 也不会等待从服务器端返回数据, 只是设置一个回调函数, 服务器响应数据回来的时候调用一下就行了。
6. 大事化小, 小事花了 : 分而治之
分而治之的基本思想是将一个规模比较大的问题分解为多个规模较小的子问题,这些子问题相互独立且与原问题性质相同。求出子问题的解,最后组合起来就可得到原问题的解。
由于子问题和原问题性质相同, 所以很多时候可以用递归。
归并排序就是一个经典的例子, 数据结构与算法书上到处都是, 这里就不在赘述了。
如果把分而治之泛化一下, 到软件设计领域, 就可以认为是把一个大问题逐步分解的过程:

思考: 你工作和学习中遇到过哪些“潜规则”? 不妨留言和大家分享下。
相关文章