2024年无人自助棋牌室的前景分析
LinkedIn前不久发布两篇文章分享了自主研发的文本分析平台Voices的概览和技术细节。LinkedIn认为倾听用户意见回馈很重要,发现反馈的主要话题、用户的热点话题和痛点,能够做出改善产品、提高用户体验等重要的商业决定。下面是整理后的技术要点。
文本分析平台及主题挖掘
文本数据挖掘是,计算机通过高级数据挖掘和自然语言处理,对非结构化的文字进行机器学习。文本数据挖掘包含但不局限以下几点:主题挖掘、文本分类、文本聚类、语义库的搭建。LinkedIn的Voices文本分析平台架构如下图,本文将侧重讲述Voices平台中的主题挖掘模块(Topic Mining)。
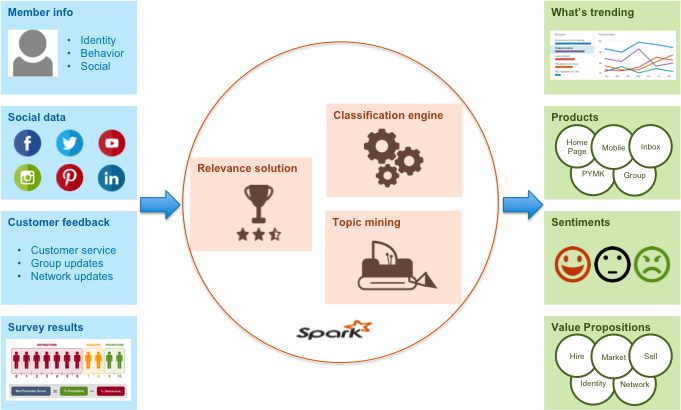
在机器学习和自然语言处理等领域,主题挖掘是寻找是主题模型,主题模型是用来在一系列文档中发现抽象主题的一种统计模型。如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。简单而言,主题挖掘就是要找到表达文章中心思想的主题词。主题挖掘的主要原因有两个:首先,文件数量迅速增长,已经依靠人工的方式实现对全部文本信息高效阅读和理解,将该流程自动化已经势在必行。其次,主题挖掘可以提高文字重度依赖应用的使用效率和产出影响,比如搜索加索引、文本总结、聚类、分类和情感分析。
从大量文字中找到主题是一个高度复杂的工作,不仅因为人的自然语言具有多层面特性,而且很难找到准确体现资料核心思想的词语。目前现有方案如:TF-IDF(Term Frequency–Inverse Document Frequency)、互信息(co-occurrence)和LDA(隐含狄利克雷分布Latent Dirichlet allocation);但是,这些算法要么是无法做到只提炼出重要主题,要么是不具高度扩展性和高效性。Voices的主题挖掘模块由LinkedIn自主研发,通过Hadoop和Spark实现,可以帮助LinkedIn规模化地进行用户反馈分析。
实现主题挖掘的四个技术步骤
Voices文本挖掘平台中的主题挖掘模块处理工作,是一个流水线处理系统,由多个自然语言模型组成的来完成。Voices的模块化步骤如下:
一. 词性标注(POS:Part-of-speech)
句子被切割成单独的词语之后,需要为每个词语加上词性标注。常见的POS为名词、动词、形容词、副词等。我们使用Java实现了斯坦福日志-线性化词性标注。每一个被分析的文件,先被切割成句子,然后分别标上词性。POS标签采用的是英文宾州树库标记。譬如,“我昨天去过了华盛顿公园”分词之后变成“我/PRP 昨天/NN 去过了/VBD 华盛顿/NNP 公园/NN” 。
二. POS模式匹配
接下来的目标是根据预定义的分词词性模式,选择出符合的POS词性标注顺序。POS模式采用正则表达式的格式,表达式可能会包含一个可递归的名词短语、一个动宾短语或者一个主谓短语等。我们观察发现,客户的反馈中,最重要的主题都是由实体名词构成,比如“主页”、“简介”;或者是事件 – 由动词名词组成的短语或动作,比如“注销账户”、“同意付款”。这使得我们创立最佳模式去寻找类似的实体词或者事件短语。为了更好地匹配,LinkedIn创立了两种不同的POS模式。
第一种适用于实体词,可递归的名词短语,名词前面可以加零或若干个修饰限定语。这样,“第二个账号”分词加标签之后为“第二个/JJ账号/NN”,最终模式匹配之后我们得到的两个短语“账号”、“第二个账号。
第二种定义的是可递归的动词短语,即包含一个或者多个连续动词。比如,短语“已经通过”对应为“已经/VBZ通过/VBN”;该短语满足模式匹配可以得出两个短语“通过”、“已经通过”。
基于上面模式对名词、动词短语的匹配方式,我们为两类不同的主题创建了下面的三种匹配模式。
- 实体词主题:一个名词短语,比如“邮箱”、“信用卡”等。
- 事件主题I:一个名词前面加一个动词的主谓结构。常见的关系到一个实体词的动作,如“申请失败”、“用户关闭”或者“上次交易失败”。
- 事件主题II:一个动词后面加上若干限定词及若干名词,动宾结构表示一件事情。此种情况下,限定词及名词可以脱离动词存在。比如“合并我的账户”、“关闭我们的旧账户”。
POS模式匹配会对所有句子的POS标签进行扫描,寻找是否有与上述三种模式匹配。每一个匹配的短语都会被当成一个候选主题。
三. 主题抽取
接下来,我们需要减少重复部分、去掉短语中无关紧要的词。主题抽取步骤如下:
- 词干提取:这是信息提取和数据挖掘中的关键技术步骤。在LinkedIn的主题挖掘中,“查看简历(view profile)”、“查看所有简历(view profiles)”、“已查看简历(viewed profile)”会被分入到同一个候选主题“查看简历(view profile)”。LinkedIn采用的是Java实现Porter词干提取算法。在词干提取合并候选主题时,会选择词频较高的词语作为最终的主题。如“view”和“profile”组成view profile。
- 去掉停止词:在选择候选主题时,还需要去掉停止词。比如文章常见的停止词:介词、代词、连词、小品词或其他辅助词语。如果最终“注销这个账户”“注销他的账户”都能被划入“注销账户”的候选主题中。LinkedIn采用的是Lextek标准版停止词。
- 合并同类词:为了进一步简化候选主题的整理,LinkedIn还自行添加了234个特定领域的停止词。去掉那些不会给候选主题添加价值的词语,比如社交网络领域的停止词“附加信息”、“联系我们”、“原消息”、“同样问题”、“网站”、“其他站点”、“点击链接”和“com”等。
- 合并语义相近的词条:最终,候选主题需要被提炼到没有同类或同义词。比如“邮箱地址”、“邮箱账号”需要被合并为一个共同主题。同样地,还可以借助WordNet之类的语库对词条进行合并,如“link”、“connection”、“association”、“partnership”和“relationship”等。LinkedIn手动添加了75组同义词。
合并特定域同类词和语义相近词可以很好地帮助候选主题的提炼,可是大部分的主题提取系统都没有重视这两项候选主题的清理策略。
四. 主题排序
经过上述步骤,最终留下来的候选主题已经都最优化。接下来,需要一个标准进行主题排序,然后可以衍生出一套主题。LinkedIn通过两个步骤进行候选主题排序:
- 我们计算每个文件中候选主题的TF-IDF值,然后根据我们的经验,我们会保留TF-IDF值最高的五个主题。TF-IDF是文件为单位的计算值,而没有考虑到文件所在的文件整个集合。
- 需要为整个文件集合产生一个单独的主题列表。LinkedIn引入了文件频率这个参数来进行整个文件集合的主题TF-IDF值的计算。
主题挖掘的业务价值
乍眼一看,这套多模块的流水线处理系统中任何模块都可以单独工作,但会有人担心无预过滤的TF-IDF计算会产生干扰和不准确的主题;不过,LinkedIn使用该系统对论坛讨论、组信息更新、博客中的用户意见文本进行主题挖掘,实践效果很好。
LinkedIn不需要人工的预览内容就可以简单地实现主题生成,同时根据文件来源的不同可以产生不同的主题。比如,账号使用者抱怨的主题可能有“主要账号”、“次要账号”、“合并账号”、“关闭账号”、“复制账号”等;简历浏览者可能关心的主题是“删除联系人”、“通讯录”、“导入联系人”、“发送邀请”和“待处理邀请”。最终,这些主题会以轮子视图的形式呈现出来,轮子内圈是实体词主题,外圈是每个实体词对应的动作。
生成主题之后,对用户抱怨反馈按照这些主题进行分类,客户服务代表据此辨别整理主题的各种情绪,从而便于用户反馈的搜索或者内容总结的生成。
此外,主题随时间的变化情况还可以用来开展趋势算法的研究。这样可以在网络媒体和社区反馈中获取重要信息。最后,还可以使用主题进行文本分类,从而降低信息维度、提高处理效率。
查看英文原文:Voices Part II: Technical Details for Topic Mining
相关文章