全开源无人自助茶室棋牌室系统源码
近日,Yahoo 开源了 TensorFlowOnSpark,这是一个大数据集群的分布式深度学习,将 TensorFlow 带到 Apache Spark 集群上。
Yahoo 在博客上表示,深度学习(DL)近年来发展迅速,为了从大量的数据中挖掘价值,需要部署分布式深度学习。现有的深度学习框架,往往需要设立单独的深度学习数据组。这强迫我们为同一个机器学习流水线创建多个程序(见下图)。维护多个独立的数据组,要求我们在它们之间传输海量数据集——这导致不必要的系统复杂性和端到端的学习延迟。
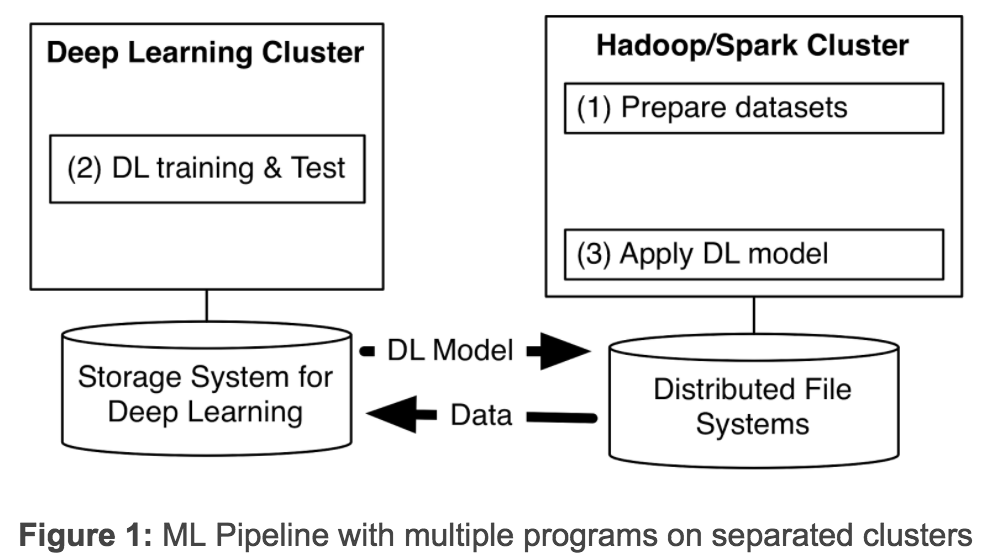
而新框架 TensorFlowOnSpark(TFoS)则支持在 Spark 和 Hadoop 集群上执行分布式 TensorFlow。如下图所示,TensorFlowOnSpark 被设计为在单个管道或程序中与 SparkSQL、MLlib和其他 Spark 库一起工作。
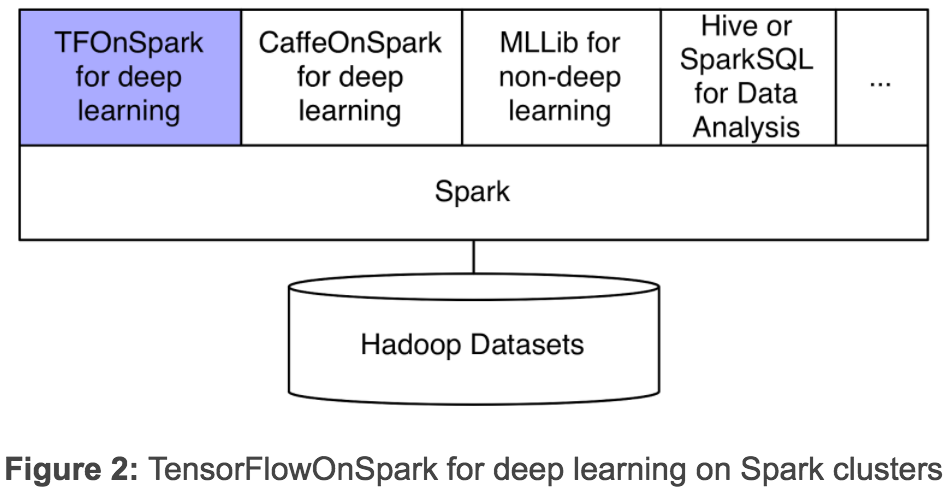
TensorFlowOnSpark 支持所有类型的 TensorFlow 程序,实现异步和同步训练和推理。它支持模型并行性和数据并行性,以及 TensorFlow 工具,如 Spar k集群上的 TensorBoard。任何 TensorFlow 程序都可以轻松地移植到 TensorFlowOnSpark 上。通常,只需要修改十行以内的 Python 代码。
TensorFlowOnSpark 支持对 Apache Spark 集群进行分布式 TensorFlow 训练和推断。它试图最小化在共享网格上运行现有 TensorFlow 程序所需的代码更改量。 它的 Spark 兼容 API 通过以下步骤来管理 TensorFlow 集群:
- 预留 – 为每个执行程序保留 TensorFlow 进程的端口,并启动数据/控制消息的侦听器。
- 启动 – 在执行器上启动 Tensorflow 主函数。
- 数据摄取
- Readers & QueueRunners – 利用 TensorFlow 的 Reader 机制直接从 HDFS 读取数据文件。
- Feeding – 使用 feed_dict 机制将 Spark RDD 数据发送到 TensorFlow 节点。 请注意,需利用 Hadoop 输入/输出格式访问 HDFS 上的 TFRecords。
- 关闭 – 关闭执行器上的 Tensorflow 工作线程和 PS 节点。
相关文章