Firefox 135.0 发布
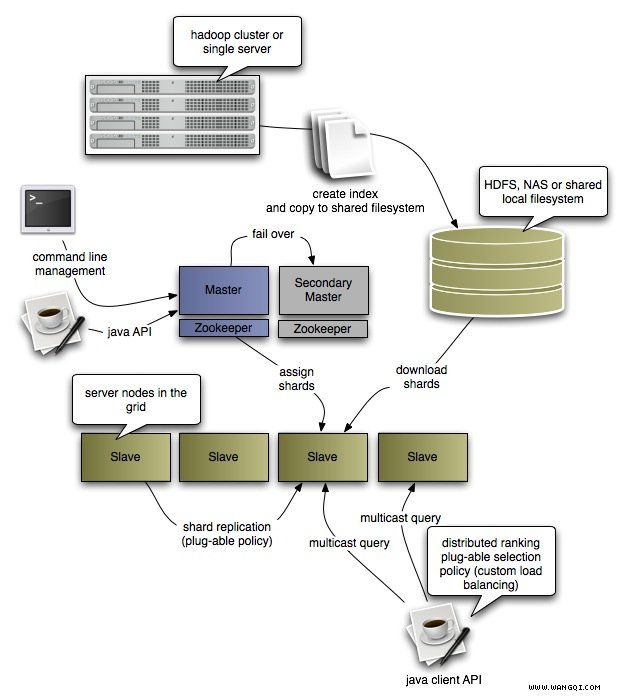
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然 不利于广大Internet用户.
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码 搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的 费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有 动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到:
每个月取几十亿网页
为这些网页维护一个索引
对索引文件进行每秒上千次的搜索
提供高质量的搜索结果
以最小的成本运作
Improvement
[NUTCH-1502] – Test for CrawlDatum state transitions
[NUTCH-1561] – improve usability of parse-metatags and index-metadata
[NUTCH-1676] – Add rudimentary SSL support to protocol-http
[NUTCH-1745] – Upgrade to ElasticSearch 1.1.0
[NUTCH-1747] – Use AtomicInteger as semaphore in Fetcher
[NUTCH-1757] – ParserChecker to take custom metadata as input
[NUTCH-1758] – IndexChecker to send document to IndexWriters
[NUTCH-1772] – Injector does not need merging if no pre-existing crawldb
[NUTCH-1782] – NodeWalker to return current node
[NUTCH-1787] – update and complete API doc overview page
[NUTCH-1794] – IndexingFilterChecker to optionally dumpText
[NUTCH-1799] – ANT Eclipse task discovers all plugin jars automatically
New Feature
[NUTCH-207] – Bandwidth target for fetcher rather than a thread count
[NUTCH-1327] – QueryStringNormalizer
[NUTCH-1590] – [SECURITY] Frame injection vulnerability in published Javadoc
相关文章









